Detecting Steganography in LLM Generated Text
in a Trusted Execution Environment (TEE)
By editing tokens in LLM output, an adversary can steganographically encode model weights for exfiltration from a datacenter. We develop a verification scheme to detect such exfiltration, and in this demo we run it inside a Trusted Execution Environment (TEE) to ensure the verifier itself cannot be compromised. Our scheme reduces exfiltration rates by ~100x, dramatically extending the time required to exfiltrate information from a datacenter.
Background
In Rinberg et al. (2025), we introduce Token DiFR: a method to verify that text was produced by a specific model running standard inference (inference verification). Applying Token DiFR to outgoing text allows you to bound the amount of information an attacker could exfiltrate per token. See blog post.
Fundamentally, creating a scheme for detecting malicious behavior forces an adversary to make a choice: they can either get caught, and deal with the consequences of being detected; or they must operate at a covert or “undetectable” level of exfiltration. This work focuses on making that undetectable regime as small as possible. Empirically, on normal user traffic, we can generally reduce undetectable exfiltration to less than 1% of the total data served (you can see this in the demo below).
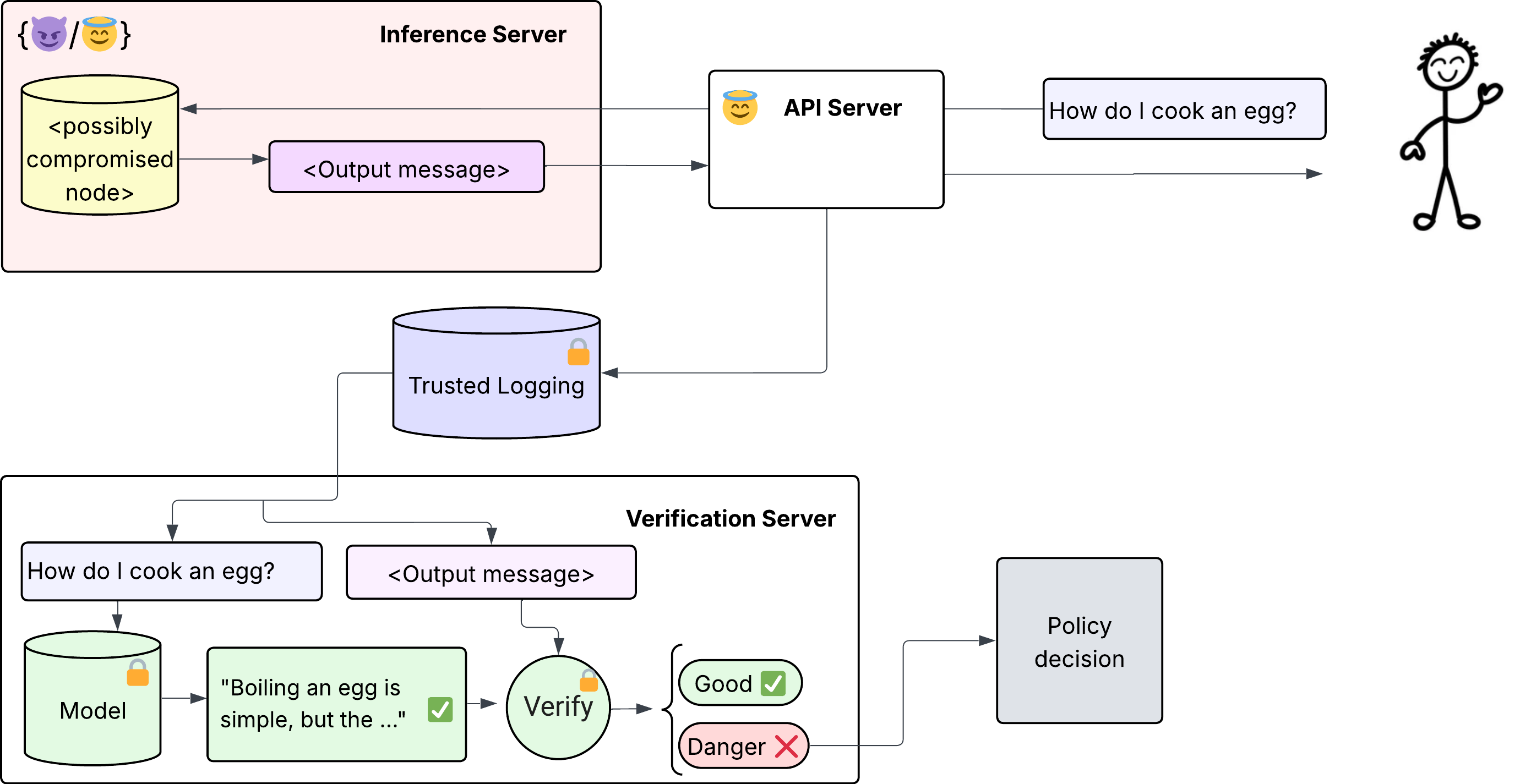
However, an attacker capable of compromising an inference server may also be capable of compromising the verification server. To remove this trust assumption, we run the verifier inside a Trusted Execution Environment (TEE) — specifically an Nvidia H200 TEE, with the enclave code built and hosted by Tinfoil.
Note: This same technology can be used to detect whether a provider is serving the model they claim to be, rather than a substitute (e.g., a quantized version). See Karvonen et al. (2025).
See diagram of inference verification detection scheme
Verify Local Text
Choose pre-generated LLM text to verify, or edit the fields below.
1. Query OpenRouter
The query goes directly to OpenRouter from your browser — the TEE is only used for verification.
Query Hyperparameters
The query is sent with the following sampling parameters (these must match during verification):
A courtesy demo key with a small budget is available so you can try the demo. If the query does not work, you can provide your own OpenRouter API key
A demo key is provided. If it stops working, you can use your own from openrouter.ai/keys.
Results
Each token is classified with the maximum amount of information an adversary could exfiltrate using that token, steganographically.
This corresponds to a —x slowdown in undetectable exfiltration by an adversary. [*]
[*] An adversary can exfiltrate more if they are okay with being detected. For preventing detectable exfiltration attempts, we can rely on techniques such as egress-limiting. See my other demonstration on compressing LLM generated text to enable stricter egress limits (compression.royrinberg.com).
* How are tokens classified and exfiltrable information computed?
Each token t is classified based on its FSSL (Fixed Seed Sampling Likelihood) score and logit rank:
where τ is the FSSL threshold and R is the rank threshold.
Exfiltrable information per token:
The empirical distribution for most "safe" tokens is that 99% of the time, there is only 1 possible token with an FSSL value above the threshold — thus an adversary can send 0 bits of information. In ~1% of cases, there are 2 possible tokens, allowing log2(2) = 1 bit. Subsequently, ~0.1% of the time there are 3 tokens with FSSL values above the threshold, and ~0.001% of the time there are 4. Thus safe tokens send:
(1 × 0.01) + (log2(3) × 0.001) + (2 × 0.00001) ≈ 0.012 bits (≈ 0.0015 bytes) of information on average.
R is the rank threshold. |Vocab| is the full vocabulary size (128,256 for Llama 3.1 8B). The total exfiltrable information is the sum over all tokens.